
こんにちは、りーりです。
最近、レバナスの騰落率の標準偏差を調べてみました。
積立投資をしていると日々の騰落率が気になります。
過去のデータを基に正規分布図を作ってみましたので、参考にしてみてください。
ただし、初心者のためあくまで参考に留めおいてくださいね。
騰落率
 りーり
りーり今まで基準価額ばかり気にしていました。
大和レバナスの積立を初めて、昨年末は含み益が出ていましたが、今年は下落基調です。
レバレッジを掛けているので、+0.01%でも増えれば基準価額は上がります。
つまり、日々の騰落率の散らばりがプラス寄りの投資信託を選択することで、利益が出やすいはずです。
誤解を恐れずに言うと、当たりが出る回数が高いガチャと言えます。
標準偏差
標準偏差、聞くだけで嫌になります。
一言で言えば、数字の散らばりです。
イメージとしては、
5+5+5 平均値 15 標準偏差0
7+6+2 平均値 15 標準偏差約2.6
15+0+0 平均値 15 標準偏差約8.6
となります。
平均値はどれも同じでも、標準偏差の値が大きいほど、数値のバラツキが広いと言えますね。
レバナス・S&P500の標準偏差は?
| 投資信託名 | 騰落率の標準偏差 |
|---|---|
| 大和レバレッジナスダック100 | 3.2931580410521675 |
| SBI−SBI・V・S&P500インデックス・ファンド | 1.680366948601636 |
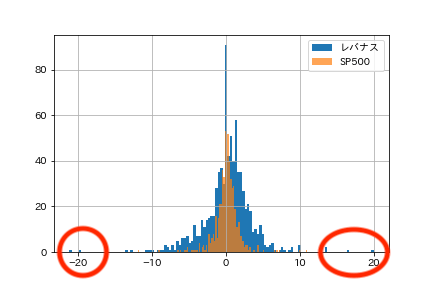
レバレッジナスダック100とS&P500の正規分布図を作りました。
レバレッジナスダックの方がプラスの帯域が多いことがわかります。
一方で、マイナス20のあたりに帯域があることを見逃してはいけません。
つまり、確率は小さいけど、大きな損失を出す可能性があることを示すものです。(ブラックスワンと言うそうです)
まぁレバナスは右側にもあるんですがね。
つまり、このような飛んだ値があるから、標準偏差が大きくなるんですね。
まとめ
騰落率の標準偏差で当たりが出る確率の高い投資信託を選ぶことが出来るかもしれませんね。
import csv
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
nas_data=input()
df_nas=pd.read_csv(nas_data,index_col=0,header=0)
df_nas=df_nas.sort_index()#日付を
df_nas.iloc[0,1]=0 #Nanを0に置換
df_nas[“前日比(円)”]=df_nas[“前日比(円)”].astype(float)#前日比を文字列からfloatに変換
df_nas[“騰落率”]=(df_nas[“基準価額(円)”].diff()/df_nas[“基準価額(円)”].shift())*100#diftで当日基準価額ー前日基準価額を算出し、shiftでdfをズラして騰落率を計算
df_nas.iloc[0,3]=0 #NANを0に置換
nas=df_nas[“騰落率”]
plt.hist(nas, bins=125)
plt.grid(True)
plt.show()
コメント